Scrum y el Release Planning
¿Qué es un Release Plan?
Un "Release Plan" o plan de entregas es un conjunto de historias de usuario (normalmente épicas) agrupadas por "releases" o versiones del producto que se ponen a disposición de los usuarios (jmbeas, 2011). Es una planificación a media distancia como una proyección hacia adelante en una serie de sprints (Mike Cohn, 2012).
El Release Planning no es parte de Scrum
El “Release Planning” es una planificación de entregas algo valiosa de hacer cuando se usa el marco Scrum, pero no es requerido por el "núcleo Scrum" o el "Scrum originario" (Scrum.org, 2011) (David Bulkin, 2011).
Se puede utilizar Scrum con éxito sin necesidad de utilizar Release Planning. Por este motivo es valioso comprender cuando puede usarse uno y cuando no.
¿Por qué no usarlo?
Puede no usarse simplemente porque no es parte de Scrum originario (determinado por los autores Ken Schwaber y Jeff Sutherland, Scrum Guide de Scrum.org y Scrum Atlas/Guide de Scrum Alliance) y no es necesario para usar Scrum satisfactoriamente.
Cuando Scrum se utiliza bien el valor potencial se crea en cada Sprint, pero si el incremento no se libera con cada Sprint o no es potencialmente utilizable, no estamos cumpliendo con el objetivo dentro del marco Scrum originario. O sea que, bajo este marco, estamos destinados a ofrecer valor operativo a los clientes de forma continua a través de iteraciones cortas. En este sentido, utilizar Release Planning puede formalizar el retraso de entrega de valor o malas prácticas. Las malas prácticas pueden ser las siguientes:
- El equipo no es capaz de crear incrementos realmente utilizable y el Release Planning afianza las prácticas de desarrollo pobre.
- Los procesos para liberar incremento utilizable son muy engorrosos, burocráticos y lentos que exigen una planificación. En este caso, el Release Planning puede colaborar en mantener estos procesos pesados en vez de procurar modificarlos para hacerlos más ágiles.
¿Por qué sí usarlo?
El Release Planning puede ser de gran utilidad bajo determinadas circunstancias.
- Cuando es difícil ofrecer una solución empresarial compleja en corto período de tiempo de un solo Sprint o se necesitan extensos períodos de prueba para satisfacer los requisitos de alta calidad (Scrum.org, 2011). Puede ser útil planificar releases o liberar un paquete de historias cuando las mismas tienen dependencias entre sí y aportan realmente valor cuando se las liberan juntas.
- A veces los clientes no quieren liberaciones frecuentes, ya que pueden crear más problemas o ruido en el mercado (Scrum.org, 2011). En ocasiones y por estrategia de negocio es conveniente planificar lanzamientos.
- Ayuda a la transparencia permitiendo comunicar las expectativas sobre lo que se puede desarrollar y en qué tiempo aproximado, lo cual, esto ayuda a que el resto de la organización pueda hacerse una idea del desarrollo y progreso (jmbeas, 2011). Este plan de aproximación para dar visibilidad "nunca debe ser tratado como un compromiso contractual ni como herramienta de presión al equipo".
- Puede servir tener un criterio de aceptación para cada “release” y asi preveer dependencias y detectar riegos (jmbeas, 2011). Puede ayudar en equipos con interdependencias y en la necesidad de coordinar entre ellos (Kent McDonald, 2013).
- Sirve, en la agilidad, como mapa topográfico que permite trazar una ruta hacia el objetivo del proyecto y así ayudar al equipo en el desarrollo ágil (Mike Cohn, 2009).
¿Por qué algunos lo usan como parte obligatoria de una metodología ágil?
Hay organizaciones que siguen una metodología basada en Scrum distinta a la ortodoxa u originaria, como la señalada por el SBOK de VMEdu, con ella se ve útil la necesidad de planificar. Por lo general se asocia a metodologías u organizaciones con cierta afinidad al PMI. Por ejemplo, para el SBOK el Release Planning se hace en el proceso de inicio de un proyecto o "Conduct Release Planning", es necesario para hacer "Release Planning Schedule" que es un input obligatorio de "Ship Deliverables" y es responsabilidad del Product Owner. El mismo es parte de la planificación inicial del proyecto y ayuda a clarificar nuevos productos o cambios en los productos existentes. O sea que en este caso el Release Plan es parte constitutiva de la metodología.
Notas:
- El
SBOK es impulsado por PMstudy que es un brand of VMEdu, Inc., el cual es
un PMI® approved R.E.P. (it is allowed to display the PMI® logo on its
website and also provide PMI® approved "Contact Hour" certificates to
students). El libro SBOK fue escrito por una treintena de personas,
ninguno de los cuales están activos en el ámbito oficial de Scrum o la
comunidad ágil y parece que no fue sancionada por ningún miembro oficial
de la comunidad Scrum. De hecho Ken Schwaber lo rechaza y dice que
Tridibesh Satpathy, autor de SBOK, quita el corazón, el alma y los
valores de Scrum con este libro (Don Kim, 2016).
¿Cómo hacer un Release Plan minimalista?
Hay que tener en cuenta que bajo el marco Scrum el Release Plan, si se hace, debe ser un documento minimalista (simple), abierto a modificaciones constante y transparentado o consensuado con el equipo de desarrollo o desarrollado con el mismo.
Para hacer un Release Plan minimalista es necesario identificar historias del MVP que representan el camino crítico (o
mínimo para tener un sub-producto funcional de valor para cliente de cara a público), identificar dependencias y riesgos; y planificar fechas o Sprints de
releases.
Además, como requisitos, es necesario tener un Product Backlog refinado (estimado y priorizado), saber la velocidad del equipo y las condiciones de satisfacción (metas para la programación, alcance , recursos) (Scrum-institute.org, 2016).
A continuación puedo mostrar un ejemplo:
Release Plan Ejemplo
Objetivo:
Este Release Plan es un documento que presenta un conjunto de historias de usuario agrupadas por sprint y releases, que se ponen a disposición de los usuarios y que conforman el MVP (sub-producto mínimo) del proyecto. Es una planificación a media distancia como una proyección hacia adelante en una serie de sprints. Este documento ayuda a brindar transparencia permitiendo comunicar las expectativas sobre lo que se puede desarrollar de aquí a X sprints. Hay que tener en cuenta que esta aproximación para dar visibilidad nunca debe ser tratada, dentro del marco ágil de trabajo, como un compromiso contractual.
Agenda de entrega
La agenda estimada es la siguiente:
Riesgos:
Identificar los riesgos principales.
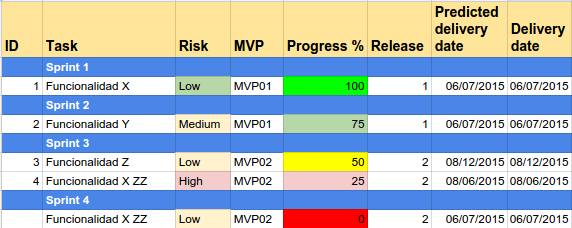
Otro ejemplo de release plan
En proyectos grandes se pueden usar features, en vez de historias, como un grado más de abstracción útil para reportar al Management sin el detalle y granularidad de historias e story points.
Una manera es listar las features (que pueden ser funcionalidades de alto nivel que engloban o contienen un conjunto de historias), a qué MVP corresponde (que es como una categoría más alta, semejante a épica), riesgo (grado de incertidumbre o riesgos), progreso (status), release (puede ser el número de release), y fechas estimadas y de release real.
Referencias:
(Scrum.org, 2011) Article: “Gone are Release Planning and the Release Burndown”, By Ralph Jocham and Henk Jan Huizer in Community Publications, Scrum.org, Saturday, October 01, 2011.
URL:
https://www.scrum.org/About/All-Articles/articleType/ArticleView/articleId/17/Gone-are-Release-Planning-and-the-Release-Burndown
(David Bulkin, 2011) Article: "Ken Schwaber and Jeff Sutherland Release Updated Scrum Guide". By David Bulkin, Infoq.com on Jul 27, 2011.
URL:
http://www.infoq.com/news/2011/07/UpdatedScrumGuide
(Don Kim, 2016) Article: The SBOK? Looks like anyone can create a PM standard these days!, By Agility and Project Leadership Blog by Don Kim.
URL:
http://www.projectmanagement.com/blog/Agility-and-Project-Leadership/7084/
(Mike Cohn, 2009) Why Do Release Planning? April 11, 2009 by Mike Cohn.
URL:
https://www.mountaingoatsoftware.com/blog/why-do-release-planning
(Mike Cohn, 2012) Release Planning: Retiring the Term but not the Technique.
Mike Cohn, 2012.
URL:
https://www.mountaingoatsoftware.com/blog/release-planning-retiring-term-not-technique
(jmbeas, 2011) Articulo: Release plan (o plan de proyecto), jmbeas, 2011. Bibliografía: “Agile Estimating and Planning” de Mike Cohn.Release plan (o plan de proyecto)
URL:
http://jmbeas.es/guias/release-plan/
(Kent McDonald, 2013) How to Do Agile Release Planning. By Kent J. McDonald - March 1, 2013.
URL:
https://www.techwell.com/techwell-insights/2013/03/how-do-agile-release-planning
(Scrum-institute.org, 2016) SCRUM RELEASE PLANNING, scrum-institute.org, 2016.
URL:
http://www.scrum-institute.org/Release_Planning.php